A painful reality of business is that customers leave. No matter how successful your business is or how relevant your products or services are, you will invariably lose customers to your competitors.
For this reason, companies have customer retention and loyalty programmes to actively deal with the risk of losing customers. In any industry or product segment, from telecoms to SaaS companies and consumer products, customer loyalty has churn management a direct impact on profitability.
Depending on the sources you look up, and what industry you are in, the cost of acquiring a new customer is five to 25 times higher than the retaining an existing customer. Frederick Reichheld, the inventor of the net promoter score and author of "Loyalty Rules! How Today's Leaders Build Lasting Relationships" discovered that an increase of just 5% in customer retention increases profits by 25% to 95%.
Understanding why customers abandon ship is crucial to building a sustainable business. We will explore how companies can use machine learning to build a churn prediction model to improve growth. But before we delve into predicting customer churn, let's take a look at what it actually is.
What is Customer Churn Rate?
Customer churn rate is a business metric that represents the percentage of customers that end their relationship with a company in a given time period. This time frame can be measured on a monthly, quarterly, or annual basis, depending on the industry and product. Subscription-based companies (think mobile service providers, SaaS, and content platforms) typically measure churn over shorter periods of time.
Customer churn is also an indication of the health of the business. Although there are several reasons why customers may drop out, some of the most common reasons are poor service or product quality, price, and other macroeconomic factors such as a recession.
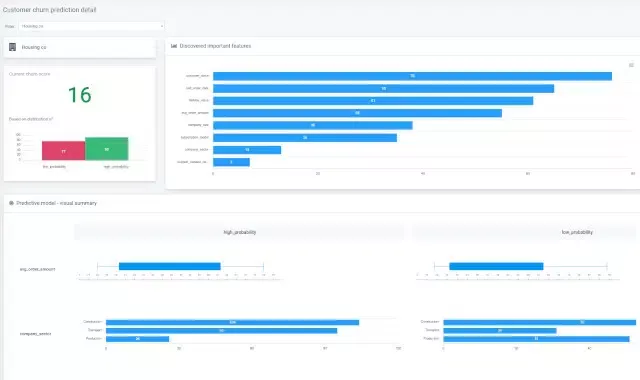
The ability to predict churn is the key to preventing it. And that is where machine learning comes in. Organisations that can prediction of churn rely exclusively on customer feedback, often overlook other variables that influence churn.
With the amount of data available to companies today, it is much easier to develop machine learning (ML) models for predicting churn. Artificial Intelligence (AI) or ML-driven churn prediction is more accurate than any other prediction model available today.
Predicting churn with Machine Learning
Companies today have access to an enormous amount of data on how their customers interact with their products or services. From CRM systems to website analytics and social engagement, companies have multiple data sources that can provide valuable insights into churn rates.
With the right data sets, machine learning algorithms can help companies identify underlying behavioural patterns common to departing customers. The algorithms can then be applied to existing customers to detect similar customer behaviour and churn indicators.
For example, a mobile service provider that wants to predict cancellations can use historical customer data to determine which customers have cancelled service or reduced their monthly billing plans. The company can then use this data to train a machine learning model to compare behavioural characteristics between churners and non-churners.
The ML model will look at attributes such as place of residence, customer lifetime, active plans, daily calls, daily data usage, monthly plans/bill amount, and number of calls to customer service to determine the likelihood of churn.
How to build a churn prediction model: A step-by-step breakdown
It is clear that historical data is a prerequisite for building a churn prediction model. However, in addition to data, there are several other factors that will determine how you build your churn prediction model. Here are the steps to creating it.
1. Determine the business case
This step is simply to understand your desired outcome of the ML algorithm. In this case, the end goal is:
- Preventing customer churn by preventively identifying high-risk customers
- Design appropriate interventions to improve retention
2. Collecting and cleaning up data
The next step is data collection - understanding which data sources will feed your churn prediction model. Companies collect customer data throughout the lifecycle via software such as CRM, web analytics, sentiment analysis tools, social listening tools, customer service software and more.
Building data capture services is one of the easiest and most effective ways to start collecting data for your churn prediction model. A big step in data preparation is transforming all this raw information into structured data.
3. Develop, extract and select characteristics
Feature engineering is a crucial part of dataset preparation - it helps determine the attributes that represent behavioural patterns related to customers' interaction with a product or service. Data scientists use feature engineering to assign measurable attributes to data points that an ML model will process to predict the likelihood of churn.
These characteristics may include customer demographic data, behaviour (in the example of the mobile phone, this may include data usage, customer service calls, use of international roaming, etc.) and contextual characteristics that describe other information about a customer, such as communication preferences, past buying behaviour or birthdays/anniversaries.
Then feature extraction standardises the variables (attributes) by isolating only those variables that contain meaningful information in the context of the business case (churn). Feature extraction limits data dimensionality (columns representing attributes in a dataset) and retains only useful data for the business case.
Feature selection refers to a data science technique that identifies previously extracted features and selects subgroups that most affect the target variable (churn). This leads to a dataset that contains only the most relevant information on features that influence churn.
4. Build a predictive model
Data analysts usually approach the prediction of churn using multiple methods, such as binary classification, logistic regression, decision trees, random forest, and others.
ML algorithms perform binary classification to divide the attributes of a target variable into two groups based on a classification rule. In this context, the target variable is churn, the outcome of which can be classified as true or false. Binary classification helps us to understand which customers dropped out and which customers stayed.
If you call on Trendskout, you don't need to put a data scientist to work, of course. That all happens in the platform. Through fast ittirations the smart AI and ML platform of Trendskout chooses the right models.
Based on this information, data scientists can then perform regression analysis to determine the relationship between the target variable (churn) and other data points that influence churn (monthly plan, data usage, service calls, etc.), in weighted values.
This will provide information on whether variables have a positive or negative relationship with churn. A positive relationship indicates a higher probability of customers dropping out and a negative relationship means that customers are less likely to drop out.
A decision tree is another effective training model for the prediction of terminations. The decision tree model uses the available characteristics and splits the data according to the values of the characteristics to obtain unique resulting groups. Here is a simple example of a decision tree:
Depending on the size of the dataset and the diversity of the feature data, you may choose to use multiple decision trees or a Random Forest.
A Random Forest is a collection of multiple decision trees, where each individual tree breaks down a classification. These classifications are binary in nature, so the classification that gets the most votes wins. So, if your Random Forest consists of five decision trees, and three of them give the same classification, then your final prediction will be determined by the majority.
5. Implement and monitor
Once you have developed the model, it must be integrated into existing software or serve as the basis for a new programme or application. You must keep a close eye on the accuracy and performance of the model.
By testing and monitoring the model's performance to adjust functions, you can improve the model's accuracy. In our example of mobile services, monitoring and testing can mean logging customer interactions and reviews.
Improve revenue with customer churn prediction
The most important factor in addressing churn is to develop a churn prediction model. The model not only tells you who your high-risk customers are, but also provides insight into the reasons why they will leave. For marketers and customer success managers, this is the holy grail of solving the leaky bucket problem - discovering the underlying reasons for customer churn.
Customer retention comes down to a company's ability to analyse and predict the motivations behind churn and, more importantly, act on it. The larger your customer base, the greater the impact of churn.
Do you want to improve your sales results with churn prediction? Interested in tapping into missed data opportunities that lead to business growth? Let's talk about how we can use machine learning to implement accurate churn prediction for your business.
Please contact us for more information.


