Künstliche Intelligenz und Maschinelles Lernen sind heute heiß diskutierte Themen in den Unternehmen und werden in den kommenden Jahren praktisch jede wirtschaftliche Aktivität verändern. Eine der KI-Anwendungen, die seit langem die Phantasie beflügelt, ist die, bei der Maschinen in Analogie zum menschlichen Gehirn Bilder verarbeiten, analysieren und ihnen Bedeutung verleihen können: die Bilderkennung. Denken Sie an den Science-Fiction-Kultklassiker Robocop aus den 1980er Jahren, in dem der Polizist Alex Murphy die Umgebung durch das Visier seines Roboters scannt und so zwischen unschuldigen Kindern und gefährlichen Gangstern unterscheiden kann. Oder viel aktueller und nicht mehr Hollywood-Fiction: die in Autos eingebauten Bilderkennungssysteme, die die Umgebung eingehend analysieren und selbstfahrende Autos sehr nahe erscheinen lassen. .
Begriffe wie Bilderkennung, Bilderkennung und Computer Vision hat inzwischen jeder schon einmal gehört. Die ersten Versuche, solche Systeme zu bauen, gehen jedoch auf die Mitte des letzten Jahrhunderts zurück, als die Grundlage für die High-Tech-Anwendungen gelegt wurde, die wir heute kennen. In diesem Blog werfen wir einen Blick auf die Entwicklung der Technologie bis zum heutigen Tag. Als nächstes sehen wir uns genauer an, welche konkreten Geschäftsfälle mit der heutigen Spitzentechnologie möglich sind. Und schließlich werfen wir einen Blick darauf, wie sich Anwendungsfälle der Bilderkennung mit der Trendskout AI-Software-Plattform realisieren lassen.
Der Aufstieg und die Entwicklung der KI-Bilderkennung als wissenschaftliche Disziplin
Pioniere aus anderen Bereichen bildeten die Grundlage für die Bilderkennung, die wir heute kennen
Die ersten Schritte in Richtung der späteren Bilderkennungstechnologie wurden in den späten 1950er Jahren unternommen. Ein einflussreicher Artikel der Neurophysiologen David Hubel und Torsten Wiesel aus dem Jahr 1959 wird oft als Ausgangspunkt zitiert. Dieses Papier hatte jedoch nichts mit dem Aufbau von Softwaresystemen zu tun. In ihrer Veröffentlichung "Rezeptive Felder einzelner Neuronen im striatischen Kortex der Katze"Hubel und Wiesel beschrieben die wichtigsten Reaktionseigenschaften der visuellen Neuronen und wie die visuellen Erfahrungen der Katzen die kortikale Architektur formen. Bei ihren Experimenten an Katzen entdeckten sie eher zufällig, dass es im primären visuellen Kortex einfache und komplexe Neuronen gibt, aber auch, dass die Bilderkennung immer mit der Verarbeitung einfacher Strukturen beginnt, wie z.B. leicht unterscheidbare Kanten von Objekten. Und so werden Schritt für Schritt Komplexität und Details aufgebaut. Dieses Prinzip ist nach wie vor das Kernprinzip der Deep Learning-Technologie, die in der computerbasierten Bilderkennung eingesetzt wird.
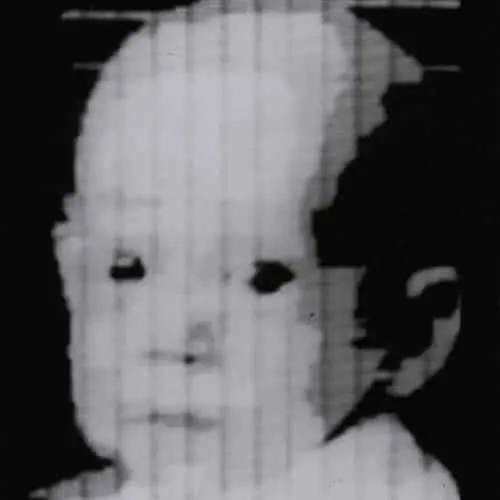
Ein weiterer Meilenstein ereignete sich etwa zur gleichen Zeit, nämlich die Erfindung des ersten digitalen Fotoscanners. Eine Gruppe von Forschern unter der Leitung von Russel Kirsch entwickelte eine Maschine, die es ermöglichte, Bilder in Zahlengitter umzuwandeln, die binäre Sprache, die Maschinen verstehen können. Ihrer bahnbrechenden Arbeit ist es zu verdanken, dass wir heute digitale Bilder auf vielfältige Weise bearbeiten können. Eines der ersten Bilder, die gescannt wurden, war ein Foto von Russells Sohn. Es war ein kleines, körniges Foto, das mit 30.976 Pixeln (176*176) aufgenommen wurde, aber heute ist es zu einem ikonischen Bild geworden.
Wachsen zu einer akademischen Disziplin
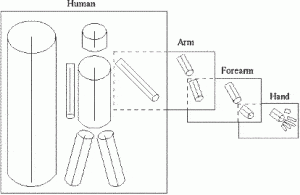
Lawrence Roberts gilt als der eigentliche Begründer der Bilderkennung oder der Computer-Vision-Anwendungen, wie wir sie heute kennen. In seiner Dissertation von 1963 mit dem Titel "Maschinelle Wahrnehmung von dreidimensionalen Körpern"Lawrence beschreibt den Prozess der Ableitung von 3D-Informationen über Objekte aus 2D-Fotos. Das von ihm entwickelte Programm diente ursprünglich dazu, 2D-Fotos in Strichzeichnungen umzuwandeln. Diese Linienzeichnungen würden dann zur Erstellung von 3D-Darstellungen verwendet werden, wobei die nicht sichtbaren Linien weggelassen werden. In seiner Dissertation beschrieb er die Prozesse, die durchlaufen werden müssen, um eine 2D-Struktur in eine 3D-Struktur umzuwandeln und wie eine 3D-Darstellung anschließend in eine 2D-Darstellung umgewandelt werden kann. Die von Lawrence beschriebenen Prozesse erwiesen sich als hervorragender Ausgangspunkt für spätere Forschungen zu computergesteuerten 3D-Systemen und Bilderkennung.
In den 1960er Jahren wurde der Bereich der künstlichen Intelligenz zu einer vollwertigen akademischen Disziplin. Für einige, sowohl Forscher als auch Gläubige außerhalb des akademischen Bereichs, war KI von ungezügeltem Optimismus über die Zukunft umgeben. Einige Forscher waren überzeugt, dass in weniger als 25 Jahren ein Computer gebaut werden würde, der den Menschen an Intelligenz übertreffen würde. Heute, mehr als 60 Jahre später, scheint dies nicht unmittelbar bevorzustehen. Einer dieser unverblümt optimistischen Denker war Seymour Papert.

Papert war Professor am KI-Labor des renommierten Massachusetts Insitute of Technology (MIT). 1966 startete er dort das "Summer Vision Project". Die Absicht war, während der Sommermonate mit einer kleinen Gruppe von MIT-Studenten zusammenzuarbeiten, um die Herausforderungen und Probleme im Bereich der Bilderkennung in Angriff zu nehmen. Die Studenten mussten eine Bilderkennungsplattform entwickeln, die Vorder- und Hintergrund automatisch segmentiert und nicht überlappende Objekte aus Fotos extrahiert. Das Projekt scheiterte und auch heute noch gibt es, trotz unbestreitbarer Fortschritte, große Herausforderungen bei der Bilderkennung. Dennoch wurde dieses Projekt von vielen als die offizielle Geburtsstunde der KI-basierten Computer Vision als wissenschaftliche Disziplin angesehen.
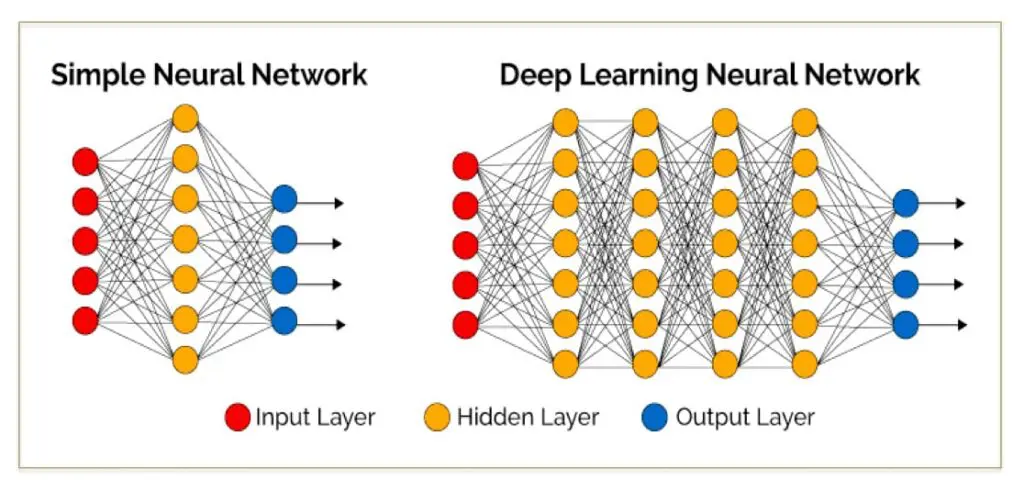
Von der Hierarchie zum neuronalen Netz
Spulen Sie vor bis 1982 und zu dem Zeitpunkt, als David Marr, ein britischer Neurowissenschaftler, die einflussreiche Arbeit "Vision: A computational investigation into the human representation and processing of visual information" veröffentlichte. Dies baut auf den Konzepten und Ideen auf, die besagen, dass die Bildverarbeitung nicht von ganzheitlichen Objekten ausgeht. Marr fügte eine wichtige neue Erkenntnis hinzu: Er stellte fest, dass das visuelle System hierarchisch funktioniert. Er erklärte, dass die Hauptfunktion unseres visuellen Systems darin besteht, 3D-Darstellungen der Umgebung zu erstellen, damit wir mit ihr interagieren können. Er führte einen Rahmen ein, in dem Algorithmen auf niedriger Ebene Kanten, Ecken, Kurven usw. erkennen und als Sprungbrett für das Verständnis von visuellen Daten auf höherer Ebene verwendet werden.
Etwa zur gleichen Zeit baute der japanische Wissenschaftler Kunihiko Fukushima ein selbstorganisierendes künstliches Netzwerk aus einfachen und komplexen Zellen, das Muster erkennen konnte und von Positionsveränderungen unbeeinflusst blieb. Dieses Netzwerk mit dem Namen Neocognitron bestand aus mehreren Faltungsschichten, deren (typischerweise rechteckige) rezeptive Felder mit Gewichtsvektoren, besser bekannt als Filter, versehen waren. Diese Filter bewegten sich über Eingabewerte (z.B. Bildpixel), führten Berechnungen durch und lösten dann Ereignisse aus, die von den nachfolgenden Schichten des Netzwerks als Eingabe verwendet wurden. Neocognitron kann somit als das erste neuronale Netzwerk bezeichnet werden, das die Bezeichnung "tief" verdient und wird zu Recht als Vorfahre der heutigen Faltungsnetzwerke angesehen.
Ab 1999 begannen immer mehr Forscher, den Weg zu verlassen, den Marr mit seiner Forschung eingeschlagen hatte, und die Versuche, Objekte anhand von 3D-Modellen zu rekonstruieren, wurden aufgegeben. Man begann, sich mit der merkmalsbasierten Objekterkennung, einer Art Bilderkennung, zu befassen. Die Arbeit von David Lowe "Objekterkennung anhand lokaler skaleninvarianter Merkmale" war ein wichtiger Indikator für diesen Wandel. Das Papier beschreibt ein visuelles Bilderkennungssystem, das Merkmale verwendet, die unveränderlich gegenüber Drehung, Standort und Beleuchtung sind. Laut Lowe ähneln diese Merkmale denen von Neuronen im inferioren temporalen Kortex, die bei Primaten an Objekterkennungsprozessen beteiligt sind.
Ausgereifte Technologie, breit einsetzbar
Seit den 2000er Jahren hat sich der Schwerpunkt daher auf die Erkennung von Objekten verlagert. Ein Schlüsselmoment in dieser Entwicklung war 2006, als Fei-Fei Li (damals Princeton Alumni, heute Professor für Informatik in Stanford) beschloss, Imagenet zu gründen. Zu dieser Zeit kämpfte Li in ihrer Forschung zum maschinellen Lernen mit einer Reihe von Hindernissen, darunter das Problem der Überanpassung. Overfitting bezieht sich auf ein Modell, bei dem Anomalien aus einem begrenzten Datensatz gelernt werden. Die Gefahr dabei ist, dass sich das Modell an Rauschen statt an die relevanten Merkmale erinnert. Da Bilderkennungssysteme jedoch nur Muster erkennen können, die bereits gesehen und trainiert wurden, kann dies zu einer unzuverlässigen Leistung bei derzeit unbekannten Daten führen. Das gegenteilige Prinzip, die Unteranpassung, führt zu einer Übergeneralisierung und versagt bei der Unterscheidung korrekter Muster zwischen Daten.

Um diese Hindernisse zu überwinden und es Maschinen zu ermöglichen, bessere Entscheidungen zu treffen, beschloss Li, einen verbesserten Datensatz zu erstellen. Das Projekt mit dem Namen Imagenet begann 2007. Nur drei Jahre später bestand Imagenet aus mehr als 3 Millionen Bildern, die alle sorgfältig beschriftet und in mehr als 5.000 Kategorien unterteilt waren. Dies war nur der Anfang und entwickelte sich zu einem enormen Schub für die gesamte Welt der Bild- und Objekterkennung.
Um die Sichtbarkeit zu erhöhen, wurde 2010 die erste Imagenet Large Scale Visual Recognition Challenge (ILSVRC) organisiert. Bei dieser Herausforderung wurden Algorithmen zur Objekterkennung und -klassifizierung in großem Maßstab bewertet. Dank dieses Wettbewerbs gab es 2012 einen weiteren großen Durchbruch in diesem Bereich. Ein Team der University of Toronto entwickelte Alexnet (benannt nach Alex Krizhevsky, dem Wissenschaftler, der das Projekt ins Leben rief), das eine Architektur für faltige neuronale Netze verwendet. Im ersten Jahr des Wettbewerbs lag die Gesamtfehlerquote der Teilnehmer bei mindestens 25%. Mit Alexnet, dem ersten Team, das Deep Learning einsetzt, gelang es ihnen, die Fehlerquote auf 15,3% zu senken. Dieser Erfolg eröffnete das enorme Potenzial der Bilderkennung als Technologie. Bis 2017 war die Fehlerquote im Wettbewerb auf unter 5% gesunken.
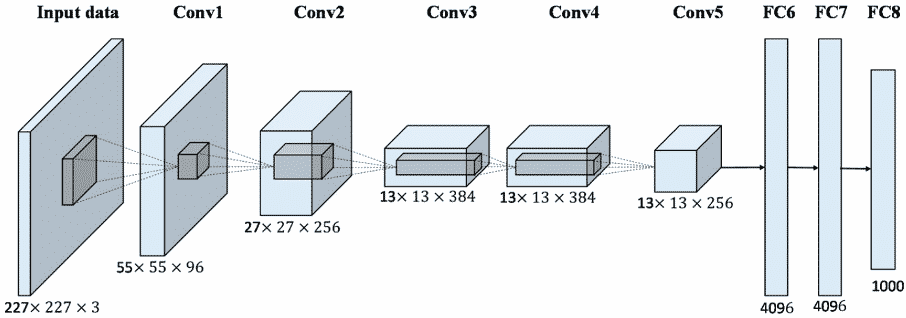
All dies bedeutete viel mehr als nur einen Wettbewerb zu gewinnen. Es wurde zweifelsfrei bewiesen, dass das Training mit Imagenet den Modellen einen großen Schub geben kann und nur noch eine Feinabstimmung erforderlich ist, um auch andere Erkennungsaufgaben zu erfüllen. Auf diese Weise trainierte faltige neuronale Netze sind eng mit dem Transferlernen verwandt. Diese neuronalen Netze werden inzwischen in vielen Anwendungen eingesetzt, z. B. schlägt Facebook selbst auf der Grundlage der Bilderkennung bestimmte Tags in Fotos vor.
Aktuelle Bilderkennungstechnologie für Geschäftsanwendungen
Qualitätskontrolle und Inspektion in Produktionsumgebungen
Der Sektor, in dem Bilderkennung oder Computer Vision-Anwendungen heute am häufigsten eingesetzt werden, ist die Produktions- oder Fertigungsindustrie. In diesem Sektor wurde und wird das menschliche Auge häufig zur Durchführung bestimmter Kontrollen herangezogen, zum Beispiel für die Produktqualität. Die Erfahrung hat gezeigt, dass das menschliche Auge nicht unfehlbar ist und externe Faktoren wie Müdigkeit die Ergebnisse beeinflussen können. Diese Faktoren in Verbindung mit den ständig steigenden Arbeitskosten haben dazu geführt, dass Computer-Vision-Systeme in diesem Sektor leicht verfügbar sind.

Bilderkennungsanwendungen eignen sich hervorragend für die Erkennung von Abweichungen oder Anomalien in großem Maßstab. Die Maschinen können darauf trainiert werden, Lackfehler oder Lebensmittel mit faulen Stellen zu erkennen, die verhindern, dass sie dem erwarteten Qualitätsstandard entsprechen. Eine weitere beliebte Anwendung ist die Inspektion beim Verpacken verschiedener Teile, bei der die Maschine prüft, ob jedes Teil vorhanden ist.
Anwendungen in Überwachung und Sicherheit
Eine weitere Anwendung, bei der das menschliche Auge häufig zum Einsatz kommt, ist die Überwachung durch Kamerasysteme. Oft müssen mehrere Bildschirme kontinuierlich überwacht werden, was eine permanente Konzentration erfordert. Mit Hilfe der Bilderkennung können Sie einer Maschine beibringen, Ereignisse zu erkennen, z. B. Eindringlinge, die nicht an einen bestimmten Ort gehören. Neben dem Sicherheitsaspekt der Überwachung gibt es noch viele andere Verwendungszwecke für sie. So können beispielsweise Fußgänger oder andere gefährdete Verkehrsteilnehmer auf Industriegeländen lokalisiert werden, um Unfälle mit schweren Maschinen zu vermeiden.

Asset Management und Projektüberwachung in den Bereichen Energie, Bau, Schienenverkehr oder Schifffahrt
Große Anlagen oder Infrastrukturen erfordern einen immensen Inspektions- und Wartungsaufwand, oft in großen Höhen oder an anderen schwer zugänglichen Stellen, unter der Erde oder sogar unter Wasser. Kleine Fehler in großen Anlagen können eskalieren und großen menschlichen und wirtschaftlichen Schaden verursachen. Bildverarbeitungssysteme können perfekt trainiert werden, um diese oft riskanten Inspektionsaufgaben zu übernehmen.
Mängel wie Rost, fehlende Schrauben und Muttern, Beschädigungen oder Gegenstände, die dort nicht hingehören, wo sie sind, können so identifiziert werden. Diese Elemente aus der Bilderkennungsanalyse können selbst Teil der Datenquellen sein, die für umfassendere Fälle von vorausschauender Wartung verwendet werden. Durch die Kombination von KI-Anwendungen kann nicht nur der aktuelle Zustand abgebildet werden, sondern diese Daten können auch zur Vorhersage zukünftiger Ausfälle oder Brüche verwendet werden.

Kartierung der Gesundheit und Qualität von Nutzpflanzen
Bilderkennungssysteme boomen auch im Agrarsektor. Die Kulturen können auf ihren allgemeinen Zustand hin überwacht werden, indem zum Beispiel kartiert wird, welche Insekten in welcher Konzentration auf den Pflanzen vorkommen. Auf diese Weise können Krankheiten vorhergesagt werden. Immer häufiger werden auch Drohnen- oder sogar Satellitenbilder verwendet, die große Anbauflächen kartieren. Anhand von Lichteinfall und -verschiebungen, die für das menschliche Auge unsichtbar sind, können chemische Prozesse in Pflanzen erkannt und Pflanzenkrankheiten in einem frühen Stadium aufgespürt werden, was ein proaktives Eingreifen ermöglicht und größere Schäden verhindert.

Automatisierung von Verwaltungsprozessen
In vielen Verwaltungsprozessen lassen sich noch große Effizienzgewinne durch die Automatisierung der Bearbeitung von Aufträgen, Bestellungen, Mails und Formularen erzielen. Eine Reihe von KI-Techniken, darunter die Bilderkennung, können zu diesem Zweck kombiniert werden. Optical Character Recognition (OCR) ist eine Technik, mit der Texte digitalisiert werden können. Der OCR fehlt jedoch eine intelligente Komponente, die den Daten eine Bedeutung verleiht. KI-Techniken wie die Named Entity Recognition werden dann verwendet, um Entitäten in Texten zu erkennen. Aber in Kombination mit Bilderkennungstechniken wird noch mehr möglich. Denken Sie an das automatische Scannen von Containern, Lastwagen und Schiffen auf der Grundlage von externen Hinweisen auf diese Transportmittel.
Bild- und Objekterkennung innerhalb der Trendskout AI Software-Plattform
Wie oben beschrieben, hat sich die Technologie hinter Bilderkennungsanwendungen seit den 1960er Jahren enorm weiterentwickelt. Heute werden für diese Art von Anwendungen Deep Learning-Algorithmen und Faltungsneuronale Netze (Convnets) verwendet. Innerhalb der Trendskout AI-Softwareplattform abstrahieren wir von den komplexen Algorithmen, die hinter dieser Anwendung stehen, und ermöglichen es auch Nicht-Datenwissenschaftlern, modernste Anwendungen mit Bilderkennung zu erstellen. Auf diese Weise machen wir als KI-Unternehmen die Technologie für ein breiteres Publikum wie Geschäftsanwender und Analysten zugänglich. Der KI-Trend Skout Software ermöglicht es auch, jeden Schritt des Prozesses, von der Etikettierung über das Training des Modells bis hin zur Steuerung externer Systeme wie z.B. der Robotik, auf einer einzigen Plattform einzurichten.
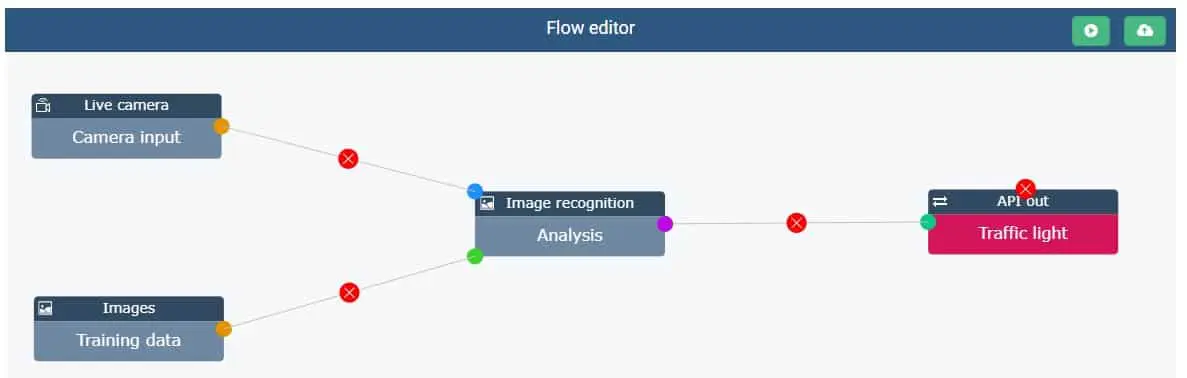
Trainingsdateneingabe und Verbindung für KI-Bildverarbeitung in Echtzeit
Es wird unterschieden zwischen einem Datensatz zum Modell Training und die Daten, die live verarbeitet werden müssen, wenn das Modell in Produktion geht. Als Trainingsdaten können Sie Video- oder Fotodateien in verschiedenen Formaten hochladen (AVI, MP4, JPEG,...). Bei der Verwendung von Videodateien teilt die Trendskout AI Software diese automatisch in einzelne Bilder auf, was die Beschriftung in einem nächsten Schritt erleichtert.
Wie bei anderen KI- oder maschinellen Lernanwendungen ist die Qualität der Daten wichtig für die Qualität der Bilderkennung. Die Schärfe und die Auflösung der Bilder haben daher Auswirkungen auf das Ergebnis: die Genauigkeit und die Verwendbarkeit des Modells. Ein guter Leitfaden ist hier, dass je schwieriger etwas für das menschliche Auge zu erkennen ist, desto schwieriger wird es auch für die künstliche Intelligenz sein.
Oftmals ist bei (Video-)Bildern nur ein bestimmter Bereich für die Durchführung einer Bilderkennungsanalyse relevant. In dem hier verwendeten Beispiel war dies eine bestimmte Zone, in der Fußgänger erkannt werden mussten. Bei Qualitätskontroll- oder Inspektionsanwendungen in Produktionsumgebungen handelt es sich häufig um eine Zone, die sich auf dem Weg eines Produkts befindet, genauer gesagt um einen bestimmten Teil des Förderbands. Daher wurde eine benutzerfreundliche Zuschneidefunktion eingebaut, um bestimmte Bereiche auszuwählen.

Beschriftung oder Kommentierung der Daten
Um Objekte oder Ereignisse erkennen zu können, muss die Trendskout KI-Software darauf trainiert werden. Dazu sollten Sie die Objekte, die vom Computer Vision System erkannt werden sollen, beschriften oder mit Anmerkungen versehen. Zu diesem Zweck müssen diese Rahmen mit Etiketten versehen werden. Innerhalb der Trendskout AI Software kann dies ganz einfach über eine Ziehen und Ablegen Funktion. Sobald ein Etikett zugewiesen wurde, wird es von der Software gespeichert und kann in den nachfolgenden Rahmen einfach angeklickt werden. Auf diese Weise können Sie alle Einzelbilder der Trainingsdaten durchgehen und alle Objekte anzeigen, die erkannt werden müssen.
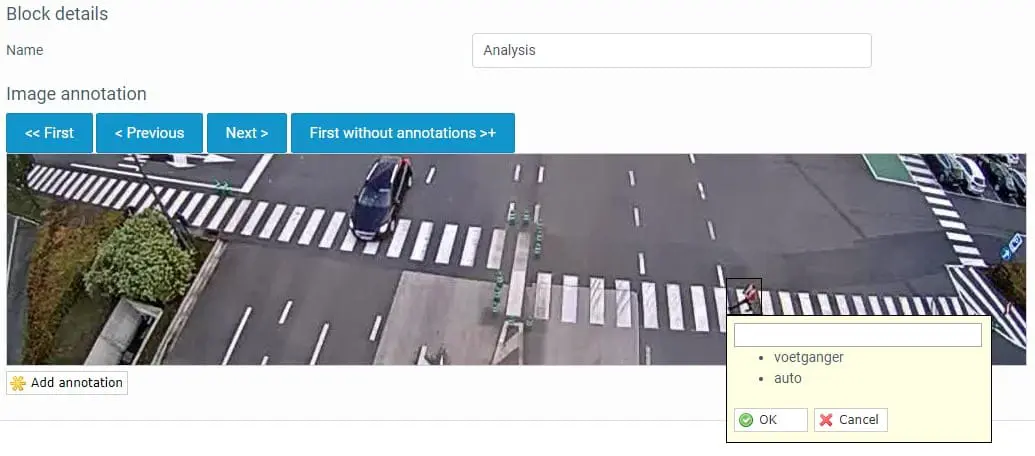
Aufbau und Training des Computer Vision- oder Bilderkennungsmodells
Sobald alle Trainingsdaten annotiert sind, kann das Deep Learning-Modell erstellt werden. Alles, was Sie tun müssen, ist auf der Trendskout AI-Plattform auf die Schaltfläche RUN zu klicken. In diesem Moment beginnt im Hintergrund die automatische Suche nach dem leistungsstärksten Modell für Ihre Anwendung. Die Trendskout KI-Software führt im Backend Tausende von Kombinationen von Algorithmen aus. Je nach Anzahl der zu verarbeitenden Bilder und Objekte kann diese Suche einige Stunden bis Tage dauern. Darauf müssen Sie natürlich nicht warten. Sobald das leistungsstärkste Modell zusammengestellt wurde, wird der Administrator benachrichtigt. Zusammen mit diesem Modell wird eine Reihe von Metriken vorgestellt, die die Genauigkeit und die Gesamtqualität des konstruierten Modells widerspiegeln.

Verwenden Sie das Modell für Ihren Business Case
Nachdem das Modell trainiert wurde, kann es in Betrieb genommen werden. Dies erfordert in der Regel eine Verbindung mit der Kameraplattform, die für die Erstellung der (Echtzeit-)Videobilder verwendet wird. Dies kann über die Funktion der Live-Kameraeingabe erfolgen, die sich über eine API mit verschiedenen Videoplattformen verbinden kann. Das ausgehende Signal besteht aus Nachrichten oder Koordinaten, die auf der Grundlage des Bilderkennungsmodells generiert werden und dann zur Steuerung anderer Softwaresysteme, der Robotik oder sogar von Ampeln verwendet werden können.
Sehen Sie in Ihrem Unternehmen Möglichkeiten für die Bild- oder Objekterkennung, aber haben Sie sich von den hohen Investitionskosten abschrecken lassen? Mit der Trendskout KI-Softwareplattform können Sie schnell und kostengünstig fortgeschrittene KI-Anwendungsfälle einrichten. Das ist unsere Mission als KI-Unternehmen: die KI zu demokratisieren. Kontakt Bitte kontaktieren Sie uns für eine unverbindliche Demo, wir helfen Ihnen gerne weiter.


