Artificiële intelligentie en machine learning zijn vandaag veelbesproken topics binnen bedrijven en zullen de komende jaren nagenoeg elke economische activiteit grondig transformeren. Eén van de AI toepassingen die al lang tot de verbeelding spreekt is deze waarbij machines, naar analogie met het menselijk brein, beelden kunnen verwerken, analyseren en er betekenis aan geven; beeldherkenning. Denk aan de science fiction cultklassieker Robocop uit de jaren 1980 waarin politieagent Alex Murphy doorheen zijn robotvizier de omgeving scant en zo onderscheid maakt tussen onschuldige kinderen en gevaarlijke gangsters. Of veel actueler, en geen Hollywood fictie meer: de beeldherkenning systemen die in wagens wordt ingebouwd en de omgeving diepgaand analyseren waardoor zelfrijdende auto’s toch heel dichtbij lijken te komen.
Termen als beeldherkenning, image recognition en computer visie (computer vision) iedereen heeft er intussen dan ook wel al over gehoord. De eerste pogingen om dergelijke systemen te bouwen dateren echter al van medio vorige eeuw toen de basis werd gelegd voor de hoogtechnologische toepassingen die we vandaag kennen. In deze blog werpen we een blik op de evolutie van de technologie tot op vandaag. Vervolgens wordt dieper ingegaan op welke concrete business cases mogelijk zijn met de huidige state of the art technologie. En tot slot werpen we een blik op image recognition use cases kunnen worden gebouwd hoe binnen het Trendskout AI software platform.
De opkomst en evolutie van AI beeldherkenning (image recognition) als wetenschappelijke discipline
Pioniers uit andere domeinen vormden de basis voor de beeldherkenning die we vandaag kennen
De eerste stappen naar wat later zou uitgroeien tot beeldherkenning- of image recognition technologie werden eind jaren 50 van vorige eeuw gezet. Vaak wordt als startpunt verwezen naar een invloedrijke paper uit 1959 van neurofysiologen David Hubel en Torsten Wiesel. Dit werkstuk had an sich nochtans niets te maken met het bouwen van softwaresystemen. In hun publicatie “Receptive fields of single neurons in the cat’s striate cortex” beschreven Hubel en Wiesel de belangrijkste reactie-eigenschappen van visuele neuronen en op welke manier de visuele ervaringen van katten de corticale architectuur vormgeeft. Tijdens hun experimenten op katten ontdekten ze, eerder bij toeval, dat er eenvoudige en complexe neuronen in de primaire visuele cortex zijn maar ook dat beeldherkenning steeds begint met de verwerking van eenvoudige structuren zoals makkelijk te onderscheiden randen van objecten. En zo wordt vervolgens stap voor stap de complexiteit en detaillering opgebouwd. Dit principe is tot op vandaag nog steeds het kernprincipe achter de deep learning technologie die ingezet wordt bij computergestuurde beeldherkenning.
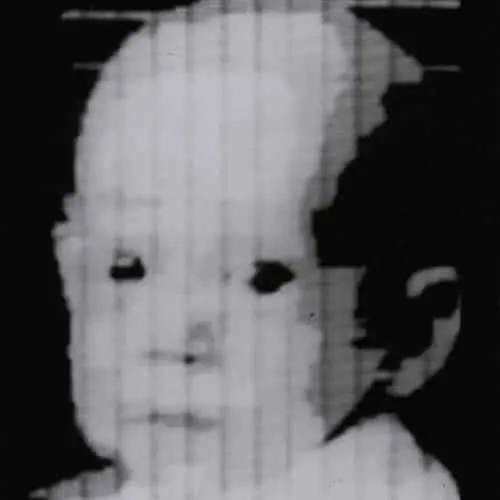
Een ander ijkpunt vond eveneens plaats rond dezelfde periode, met name de uitvinding van de eerste digitale fotoscanner. Een groep onderzoekers onder leiding van Russel Kirsch ontwikkelden een machine die het mogelijk maakte om beelden om te zetten in rasters (grids) van getallen, de binaire taal die machines kunnen begrijpen. Het is dankzij hun grensverleggend werk dat we vandaag digitale beelden op diverse manieren kunnen verwerken. Eén van de eerste foto’s die werd gescand, was een foto van zijn zoontje van Russell. Het was een kleine, korrelige foto vastgelegd op 30.976 pixels (176*176) maar is vandaag uitgegroeid tot een iconisch beeld.
Uitgroei tot een academische discipline
Als echte grondlegger van de beeldherkenning of computer vision toepassingen zoals we ze vandaag kennen wordt naar Lawrence Roberts verwezen. In zijn doctoraatsthesis uit 1963 getiteld “Machine perception of three-dimensional solids” beschrijft Lawrence het proces om 3D informatie van objecten af te leiden uit 2D foto’s. De initiële bedoeling van het programma dat hij ontwikkelde was om 2D foto’s om te zetten in lijntekeningen. Op basis van deze lijntekeningen zouden dan 3D representaties worden opgebouwd waarbij de niet zichtbare lijnen achterwege werden gelaten. In zijn thesis omschreef hij de processen die moesten doorlopen worden om een 2D constructie om te zetten naar een 3D constructie en hoe daaropvolgend een 3D weergave kan omgezet worden in een 2D weergave. De door Lawrence beschreven processen bleken een uitstekende aanzet voor latere onderzoeken naar computergestuurde 3D systemen en beeldherkenning.
In de jaren 60 werd het domein artificiële intelligentie een volwaardige academische discipline. Bij sommigen, zowel onderzoekers als believers buiten het academische veld, heerste rond AI een ongebreideld optimisme over wat de toekomst zou brengen. Een aantal onderzoekers waren ervan overtuigd dat in minder dan 25 jaar tijd een computer zou worden gebouwd die de mens het nakeken gaf qua intelligentie. Vandaag, ruim 60 jaar later blijkt dit nog niet meteen dichtbij. Eén van deze uitgesproken optimistische denkers was Seymour Papert.

Papert was professor aan het AI lab van het gereputeerde Massachusetts Insitute of Technology (MIT) en in 1966 lanceerde hij daar het “Summer Vision Project”. De intentie was om met een kleine groep van MIT studenten tijdens de zomermaanden de uitdagingen en problemen die het image recognition domein kende eventjes aan te pakken. De studenten moesten een beeldherkenning platform ontwikkelen dat automatisch segmentatie maakte van voor- en achtergrond en niet overlappende objecten kon extraheren uit foto’s. Het project draaide uit op een sisser en zelfs vandaag zijn er ondanks de ontegensprekelijke vooruitgang nog steeds grote uitdagingen rond beeldherkenning. Desalniettemin werd dit project door velen gezien als de officiële geboorte van op AI gebaseerde computer vision als een wetenschappelijke discipline.
Van hiërarchie naar neuraal netwerk
Fast forward naar 1982 en het moment waarop David Marr, een Brits neurowetenschapper, de invloedrijke paper getiteld “Vision: A computational investigation into the human representation and processing of visual information” publiceert. Deze bouwde verder op de concepten en ideeën die stelden dat beeldverwerking niet start vanuit holistische objecten. Marr voegde hier nog een belangrijk nieuw inzicht aan toe: hij stelde vast dat het visuele systeem werkt op een hiërarchische manier. Hij stelde dat de belangrijkste functie van ons visuele systeem is om 3D representaties te creëren van de omgeving zodat we hiermee kunnen interageren. Hij introduceerde een framework waarbij algoritmen op laag niveau randen, hoeken, rondingen etc. detecteren en worden gebruikt als stepping stones naar het begrijpen van visuele data op een hoger niveau.
Op nagenoeg hetzelfde moment bouwde een Japans wetenschapper, Kunihiko Fukushima, een zichzelf organiserend artificieel netwerk van eenvoudige en complexe cellen die patronen konden herkennen en niet beïnvloed werden door positieveranderingen. Dit netwerk, Neocognitron genoemd, bestond uit diverse convolutionele lagen waarvan de (typisch rechthoekige) receptieve velden gewichtsvectoren, beter bekend als filters, hadden. Deze filters schoven over invoerwaarden (zoals beeldpixels), voerden berekeningen uit en triggerden vervolgens gebeurtenissen die als invoer gebruikt werden door volgende lagen van het netwerk. Neocognitron kan hiermee bestempeld worden als het eerste neuraal netwerk dat het etiket “deep” verdiende en wordt dan ook terecht gezien als de voorvader van de hedendaagse convolutionele netwerken.
Vanaf 1999 begonnen meer en meer onderzoekers af te stappen van de weg die Marr was ingeslagen met zijn onderzoek en werden de pogingen om objecten te reconstrueren aan de hand van 3D modellen gestaakt. Men begon de inspanningen meer te oriënteren richting een op kenmerken gebaseerde objectherkenning (feature based object recognition), een soort beeldherkenning. Het werk van David Lowe “Object Recognition from Local Scale-Invariant Features” was een belangrijke indicator van deze shift. In de paper wordt een visueel beeldherkenningssyteem beschreven die kenmerken gebruikt die onveranderlijk zijn van rotatie, locatie en verlichting. Deze kenmerken lijken volgens Lowe op de eigenschappen van neuronen in de inferieure temporale cortex die betrokken zijn bij objectdetectieprocessen van primaten.
Mature technologie, op grote schaal inzetbaar
Sinds de jaren 2000 is de focus dus verschoven naar het herkennen van objecten. Een belangrijk moment in deze evolutie vond plaats in 2006 wanneer Fei-Fei Li (toen Princeton Alumni, vandaag Professor Computer Science op Stanford) besloot om Imagenet op te richten. Li worstelde op dat moment met een aantal obstakels in haar machine learning onderzoek, onder meer met het probleem van overfitting. Overfitting verwijst naar een model waarbij onregelmatigheden worden aangeleerd vanuit een beperkte dataset. Het gevaar hierbij is dat het model mogelijk ruis onthoudt in plaats van de relevante kenmerken. Omdat image recognition systemen echter alleen patronen kunnen herkennen op basis van wat al gezien en getraind is, kan dit zorgen voor onbetrouwbare prestaties voor op dat moment onbekende gegevens. Het tegenovergestelde principe, underfitting zorgt dan weer voor een over-generalisatie en slaagt er niet in correcte patronen tussen gegevens onderscheiden.

Om deze hindernissen te overwinnen en machines betere beslissingen te laten nemen besloot Li om een verbeterde dataset uit te bouwen. Het project dat de naam Imagenet meekreeg kende zijn aanvang in 2007. Amper drie jaar later bestond Imagenet uit meer dan 3 miljoen afbeeldingen, allen zorgvuldig gelabeled en gesegmenteerd in meer dan 5000 categorieën. Dit bleek slechts het begin en groeide uit tot een enorme boost voor de volledige image& object recognition wereld.
Om verder aan visibiliteit te winnen werd in 2010 door Imagenet een eerste Imagenet Large Scale Visual Recognition Challenge (ILSVRC) georganiseerd. Hierin werden algoritmen voor objectdetectie en classificatie op grote schaal geëvalueerd. Dankzij deze wedstrijd kwam er in 2012 opnieuw een grote doorbraak in het domein. Een team van de universiteit van Toronto kwam met Alexnet (vernoemd naar Alex Krizhevsky, de wetenschapper die het project trok) op de proppen, dat een convolutionele neurale netwerkarchitectuur gebruikte. Het eerste jaar van de competitie lag de algemene error rate van de deelnemers op minimaal op 25%. Met Alexnet, het eerste team dat deep learning gebruikte, slaagde men erin om de foutenlast te verlagen tot 15,3%. Door dit succes ontluikte het enorme potentieel van image recognition of beeldherkenning als technologie. Tegen 2017 was de error rate in de competitie onder de 5% gezakt.
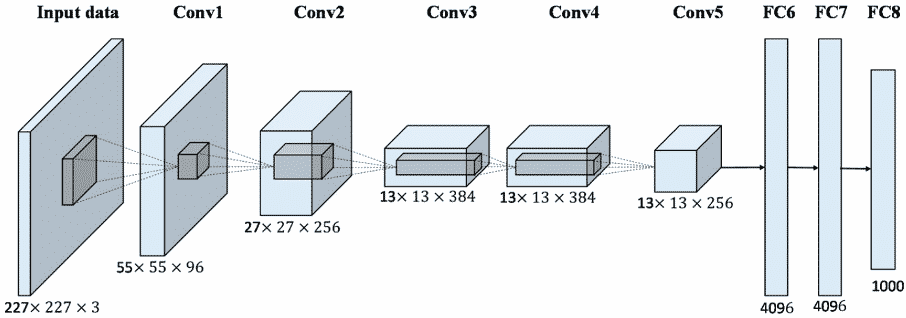
Dit alles betekende veel meer dan enkel het winnen van een wedstrijd. Het bewees ontegensprekelijk dat training via Imagenet de modellen een grote boost kon geven, waardoor enkel nog finetuning was vereist om ook andere herkenningstaken uit te voeren. Convolutionele neurale netwerken die op deze manier getraind worden zijn nauw verbonden met transfer learning. Deze neurale netwerken vinden vandaag vlot ingang in vele toepassingen, denk aan bijvoorbeeld aan hoe Facebook zelf bepaalde tags suggereert in foto’s a.d.h.v. beeldherkenning.
De huidige Beeldherkenning of image recognition technologie ingezet voor business toepassingen
Kwaliteitscontrole en inspectie in productie omgevingen
De sector waarin beeldherkenning of computer vision toepassingen vandaag het vaakst worden ingezet is de productie- of maakindustrie. In deze sector werd, en wordt nog steeds, vaak beroep gedaan op het menselijk oog om bepaalde controles uit te voeren, onder andere voor productkwaliteit. Uit ervaring is gebleken dat het menselijk oog niet onfeilbaar is en externe factoren zoals vermoeidheid een impact kunnen hebben op de resultaten. Deze factoren in combinatie met de almaar stijgende arbeidskosten zorgden ervoor dat computer visie systemen vlot ingang vonden in deze sector.

Beeldherkenningstoepassingen lenen er zich perfect toe om op grote schaal afwijkingen of anomalieën te ontdekken. Machines kunnen getraind worden om oneffenheden in lakwerk te ontdekken of voedingsmiddelen te detecteren die rotte plekken bevatten waardoor ze niet voldoen aan de verwachte kwaliteitsnorm. Een andere populaire toepassing is de controle bij het inpakken van diverse onderdelen waarbij de machine de controle uitvoert om te beoordelen of elk onderdeel aanwezig is.
Toepassingen in bewaking en veiligheid
Een andere toepassing waarvoor het menselijk oog vaak wordt ingeschakeld is het surveilleren via camerasystemen. Dikwijls moeten verschillende schermen voortdurend in het oog te worden gehouden waardoor permanente concentratie is vereist. Via image recognition kan een machine worden aangeleerd om events te herkennen, zoals indringers die niet thuishoren op een bepaalde locatie. Los van het security aspect rond bewaking zijn er vele andere gebruiksmogelijkheden onder de ruimere noemer van veiligheid. Zo kunnen bijvoorbeeld voetgangers of andere zwakke weggebruikers op industriële sites worden gelokaliseerd om incidenten met zwaar materieel te voorkomen.

Asset management en project monitoring in energie, bouw, spoor of scheepvaart
Grote installaties of infrastructuur vergen immense inspanningen inzake inspectie en onderhoud, niet zelden ook op grote hoogten of op andere moeilijk bereikbare plaatsen, ondergronds of zelfs onder water. Kleine defecten aan grote installaties kunnen escaleren en grote menselijke en economische schade veroorzaken. Visiesystemen kunnen perfect getraind worden om deze dikwijls risicovolle inspectietaken over te nemen.
Defecten zoals roest, ontbrekende bouten en moeren, beschadigingen of objecten die niet thuishoren op de plaats waar ze zich bevinden kunnen zo in kaart worden gebracht. Deze elementen uit de beeldherkenningsanalyse kunnen zelf onderdeel zijn van de databronnen die gebruikt worden voor ruimere predictive maintenance cases. Door het combineren van AI toepassingen wordt dan niet enkel de huidige staat in kaart gebracht maar zal deze data ook gebruikt kunnen worden om toekomstige defecten of breuken te voorspellen.

Gezondheid en kwaliteit van gewassen in kaart brengen
Ook in de agrarische sector kennen image recognition systemen steile opgang. Gewassen kunnen worden gemonitord op globale conditie en door bijvoorbeeld in kaart te brengen welke insecten in welke concentratie terug te vinden zijn op gewassen. Op deze manier kunnen ziektes worden voorspeld. Meer en meer wordt ook gebruikt gemaakt van drone- of zelfs satellietbeelden die grote oppervlakten gewassen in kaart brengen. Op basis van lichtinval en -schakeringen, onzichtbaar voor het menselijk oog, kunnen chemische processen in planten worden opgespoord en kunnen gewasziektes in een vroeg stadium worden opgespoord waardoor proactief kan ingegrepen worden en grotere schade worden vermeden.

Automatisatie van administratieve processen
In tal van administratieve processen zijn nog grote efficiëntiewinsten te boeken door het automatiseren van de verwerking van orders, bestelbonnen, mails en formulieren. Hiervoor kunnen een aantal AI technieken, waaronder image recognition, worden gecombineerd. Optical Character Recognition (OCR) is een techniek die kan gebruikt worden om teksten te digitaliseren. Bij OCR ontbreekt echter een slimme component die betekenis geeft aan de data. AI-technieken zoals named enitity recognition worden dan gebruikt om entiteiten op te sporen in teksten. Maar in combinatie met image recognition technieken wordt nog meer mogelijk. Denk aan het automatisch scannen van containers, vrachtwagens en schepen op basis van externe vermeldingen op deze transportmiddelen.
Image & object recognition binnen het Trendskout AI software platform
De technologie die achter image recognition toepassingen schuilt is zoals hierboven beschreven sinds de jaren 1960 enorm geëvolueerd. Vandaag worden deep learning algoritmen en convolutionele neurale netwerken (convnets) ingezet voor dit soort toepassingen. Binnen het Trendskout AI software platform maken we abstractie van de complexe algoritmiek die schuilgaat achter deze toepassing en maken we het mogelijk om als niet-datawetenschapper ook state of the art toepassingen met beeldherkenning (image recognition) te gaan bouwen. Op deze manier maken we als AI bedrijf de technologie toegankelijk voor een ruimer publiek zoals business users en analisten. De Trendskout AI software maakt het daarenboven mogelijk om elke stap van dit proces, gaande van labeling over het trainen van het model tot het aansturen van externe systemen zoals robotica, op te zetten binnen één en hetzelfde platform.
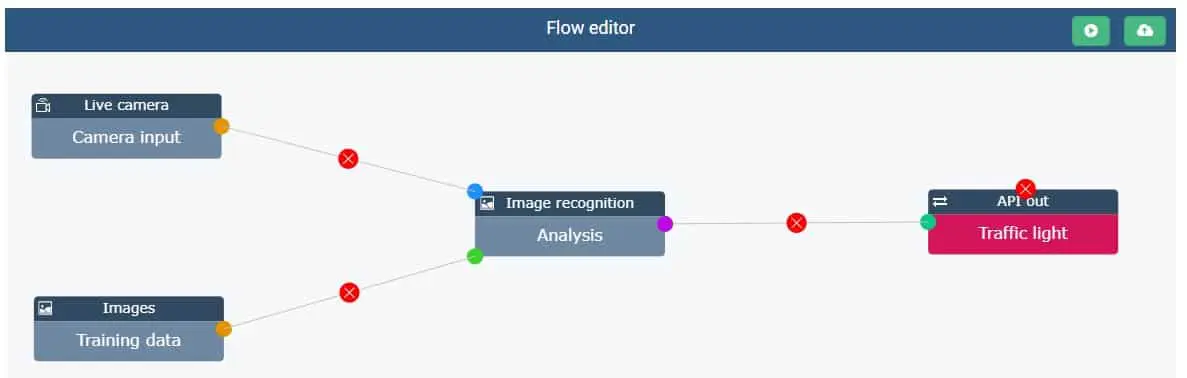
Input van trainingsdata en connectie voor real time AI beeldverwerking
Er wordt een onderscheid gemaakt tussen een dataset om het model te trainen en de data die live zal moeten verwerkt worden wanneer het model in productie wordt geplaatst. Als trainingsdata kan gekozen worden voor het uploaden van video- of fotobestanden in diverse formaten (AVI, MP4, JPEG,…). Wanneer er videobestanden worden gebruikt zal de Trendskout AI software deze automatisch opsplitsen in afzonderlijke frames, wat het labelen in een volgende stap vergemakkelijkt.
Net zoals bij andere AI of machine learning toepassingen is ook de kwaliteit van de data belangrijk voor de kwaliteit van de beeldherkenning of image recognition. De scherpte en resolutie van de beelden zullen dus een impact hebben op het resultaat: de accuraatheid en inzetbaarheid van het model. Een goede leidraad hierbij is dat hoe moeilijker iets herkenbaar is voor het menselijk oog, hoe moeilijker dit ook zal zijn voor de artificiële intelligentie.
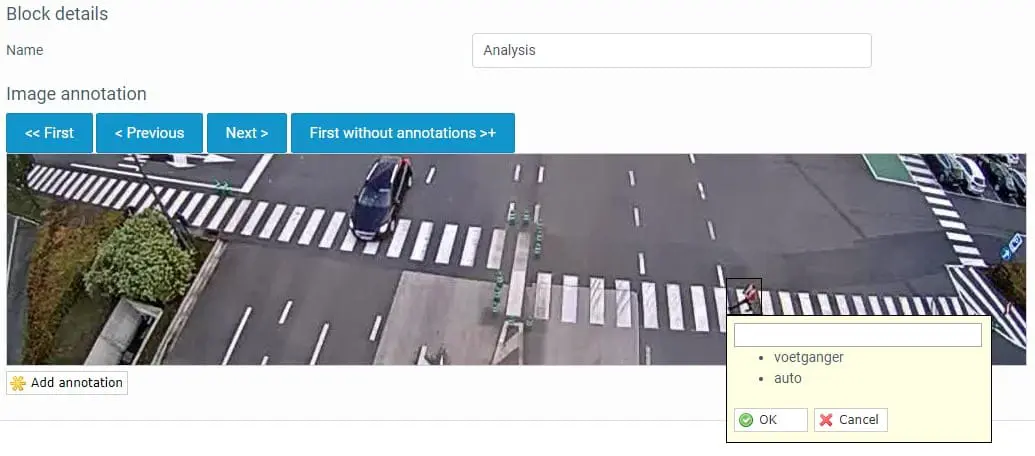
Vaak is het zo dat in (video)beelden slechts een bepaalde zone relevant is om een beeldherkenningsanalyse op uit te voeren. In het voorbeeld dat hier gebruikt wordt, betrof dit een bepaalde zone waarin voetgangers dienden gedetecteerd te worden. Bij toepassingen inzake kwaliteitscontrole of inspectie in productieomgevingen is dit dikwijls een zone die zich op het traject bevindt dat een product aflegt, meer specifiek een bepaald deel van de transportband. Om bepaalde zones te gaan selecteren werd daarom een gebruiksvriendelijke cropping functie ingebouwd.

Het labelen of annoteren van de data
Om objecten of gebeurtenissen te herkennen moet de Trendskout AI-software daarop getraind worden. Dit dient te gebeuren door het labelen of annoteren van de objecten die door het computer vision systeem moeten gedetecteerd worden. Om dit te doen dienen labels te worden aangebracht op die frames. Binnen de Trendskout AI-software kan dit eenvoudig gebeuren via een drag & drop functie. Eens een bepaald label eenmaal werd toegekend wordt dit label onthouden door de software en kan dit vervolgens simpelweg aangeklikt worden bij de daaropvolgende frames. Doorloop zo alle frames van de trainingsdata en duid alle te herkennen objecten aan.
Bouwen en trainen van het computer vision of image recognition model
Eens alle trainingsdata geannoteerd is kan het deep learning model worden gebouwd. Het enige wat u hiervoor hoeft te doen is op de RUN knop in het Trendskout AI platform klikken. Op dat moment start in de achtergrond de geautomatiseerde zoektocht naar het beste presterende model voor uw toepassing. De Trendskout AI software voert daartoe in de backend duizenden combinaties van algoritmen uit. Deze zoektocht kan, afhankelijk van het aantal te verwerken frames en objecten een aantal uren tot dagen in beslag nemen. U hoeft hier uiteraard niet op te wachten. Op het moment dat het best presterend model samengesteld is, krijgt de beheerder hiervan een melding. Samen met dit model worden ook een aantal metrieken gepresenteerd die weerspiegelen hoe hoog de accuraatheid en algemene kwaliteit van het gebouwde model is.

Het model inzetten voor uw business case
Nadat het model getraind is kan het in gebruik worden gesteld. Hiertoe dient er doorgaans geconnecteerd te worden met het cameraplatform dat gebruikt wordt om de (real time) videobeelden te maken. Dit kan via de live camera input feature die via API de connectie kan leggen met diverse videoplatformen. Het uitgaande signaal bestaat uit berichten of coördinaten die worden gegenereerd op basis van het image recognition model waarmee dan andere softwaresystemen, robotica of zelfs verkeerslichten kunnen worden aangestuurd.
Ziet u zelf opportuniteiten binnen uw onderneming voor beeld- of objectherkenning maar hield de grote investeringskost u tegen? Met het Trendskout AI software platform kan u snel en voordelig geavanceerde AI use cases opzetten. Dat is dan ook onze missie als AI bedrijf: het democratiseren van AI. Contacteer ons voor een vrijblijvende demo, we helpen u graag verder.


