Artificial intelligence and machine learning are hot topics within companies today and will transform virtually every economic activity in the coming years. One of the AI applications that has long appealed to the imagination is where machines, by analogy with the human brain, can process, analyze and give meaning to images. Think of the science fiction cult classic Robocop from the 1980s in which police officer Alex Murphy scans the environment through his robot visor and thus distinguishes between innocent children and dangerous gangsters. Or much more recent, and no Hollywood fiction: computer vision systems that are built into cars and analyze the environment in-depth, enabling self-driving cars.
Everyone has heard about terms such as image recognition, image recognition and computer vision. However, the first attempts to build such systems date back to the middle of the last century when the foundations for the high-tech applications we know today were laid. In this blog, we take a look at the evolution of the technology to date. Subsequently, we will go deeper into which concrete business cases are now within reach with the current technology. And finally, we take a look at how image recognition use cases can be built within the Trendskout AI software platform.
The emergence and evolution of AI image recognition as a scientific discipline
Pioneers from other fields formed the basis for the discipline.
The first steps towards what would later become image recognition technology were taken in the late 1950s. An influential 1959 paper by neurophysiologists David Hubel and Torsten Wiesel is often cited as the starting point. However, this paper had nothing to do with building software systems. In their publication "Receptive fields of single neurons in the cat's striate cortex" Hubel and Wiesel described the key response properties of visual neurons and how cats' visual experiences shape cortical architecture. During their experiments on cats, they discovered, rather by chance, that there are simple and complex neurons in the primary visual cortex but also that image recognition always starts with the processing of simple structures such as easily distinguishable edges of objects. And so, step by step, complexity and detail are built up. This principle is still the core principle behind deep learning technology used in computer-based image recognition.
Another benchmark also occurred around the same time, namely the invention of the first digital photo scanner. A group of researchers led by Russel Kirsch developed a machine that made it possible to convert images into grids of numbers, the binary language that machines can understand. It is thanks to their groundbreaking work that today we can process digital images in a variety of ways. One of the first images to be scanned was a photograph of Russell's son. It was a small, grainy photo captured at 30,976 pixels (176*176) but has become an iconic image today.
Growing into an academic discipline
Lawrence Roberts is referred to as the real founder of image recognition or computer vision applications as we know them today. In his 1963 doctoral thesis entitled "Machine perception of three-dimensional solids"Lawrence describes the process of deriving 3D information about objects from 2D photographs. The initial intention of the program he developed was to convert 2D photographs into line drawings. These line drawings would then be used to build 3D representations, leaving out the non-visible lines. In his thesis he described the processes that had to be gone through to convert a 2D structure to a 3D one and how a 3D representation could subsequently be converted to a 2D one. The processes described by Lawrence proved to be an excellent starting point for later research into computer-controlled 3D systems and image recognition.
In the 1960s, the field of artificial intelligence became a fully-fledged academic discipline. For some, both researchers and believers outside the academic field, AI was surrounded by unbridled optimism about what the future would bring. Some researchers were convinced that in less than 25 years, a computer would be built that would surpass humans in intelligence. Today, more than 60 years later, this does not appear to be imminent. One of these outspoken optimistic thinkers was Seymour Papert.

Papert was a professor at the AI lab of the renowned Massachusetts Insitute of Technology (MIT), and in 1966 he launched the "Summer Vision Project" there. The intention was to work with a small group of MIT students during the summer months to tackle the challenges and problems that the image recognition domain was facing. The students had to develop an image recognition platform that automatically segmented foreground and background and extracted non-overlapping objects from photos. The project ended in failure and even today, despite undeniable progress, there are still major challenges in image recognition. Nevertheless, this project was seen by many as the official birth of AI-based computer vision as a scientific discipline.
From hierarchy to neural network
Fast forward to 1982 and the moment when David Marr, a British neuroscientist, published the influential paper "Vision: A computational investigation into the human representation and processing of visual information". This built on the concepts and ideas that stated that image processing does not start from holistic objects. Marr added an important new insight: he established that the visual system works in a hierarchical way. He stated that the main function of our visual system is to create 3D representations of the environment so that we can interact with it. He introduced a framework in which low-level algorithms detect edges, corners, curves, etc. and are used as stepping stones to understanding higher-level visual data.
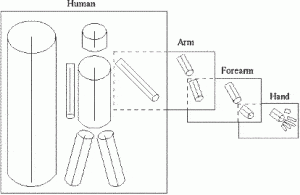
At about the same time, a Japanese scientist, Kunihiko Fukushima, built a self-organising artificial network of simple and complex cells that could recognise patterns and were unaffected by positional changes. This network, called Neocognitron, consisted of several convolutional layers whose (typically rectangular) receptive fields had weight vectors, better known as filters. These filters slid over input values (such as image pixels), performed calculations and then triggered events that were used as input by subsequent layers of the network. Neocognitron can thus be labelled as the first neural network to earn the label "deep" and is rightly seen as the ancestor of today's convolutional networks.
From 1999 onwards, more and more researchers started to abandon the path that Marr had taken with his research and the attempts to reconstruct objects using 3D models were discontinued. Efforts began to be directed towards feature-based object recognition, a kind of image recognition. The work of David Lowe "Object Recognition from Local Scale-Invariant Features" was an important indicator of this shift. The paper describes a visual image recognition system that uses features that are immutable from rotation, location and illumination. According to Lowe, these features resemble those of neurons in the inferior temporal cortex that are involved in object detection processes in primates.
Mature technology, widely deployable
Since the 2000s, the focus has thus shifted to recognising objects. A key moment in this evolution occurred in 2006 when Fei-Fei Li (then Princeton Alumni, today Professor of Computer Science at Stanford) decided to found Imagenet. At the time, Li was struggling with a number of obstacles in her machine learning research, including the problem of overfitting. Overfitting refers to a model in which anomalies are learned from a limited data set. The danger here is that the model may remember noise instead of the relevant features. However, because image recognition systems can only recognise patterns based on what has already been seen and trained, this can result in unreliable performance for currently unknown data. The opposite principle, underfitting, causes an over-generalisation and fails to distinguish correct patterns between data.

To overcome these obstacles and allow machines to make better decisions, Li decided to build an improved dataset. The project, named Imagenet, began in 2007. Just three years later, Imagenet consisted of more than 3 million images, all carefully labelled and segmented into more than 5,000 categories. This was just the beginning and grew into a huge boost for the entire image & object recognition world.
In order to gain further visibility, a first Imagenet Large Scale Visual Recognition Challenge (ILSVRC) was organised in 2010. In this challenge, algorithms for object detection and classification were evaluated on a large scale. Thanks to this competition, there was another major breakthrough in the field in 2012. A team from the University of Toronto came up with Alexnet (named after Alex Krizhevsky, the scientist who pulled the project), which used a convolutional neural network architecture. In the first year of the competition, the overall error rate of the participants was at least 25%. With Alexnet, the first team to use deep learning, they managed to reduce the error rate to 15.3%. This success unlocked the huge potential of image recognition as a technology. By 2017, the error rate in the competition had dropped below 5%.
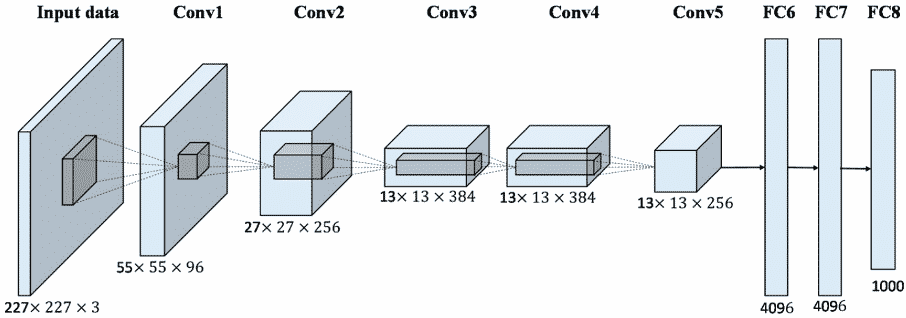
All this meant much more than just winning a competition. It proved beyond doubt that training via Imagenet could give the models a big boost, requiring only fine-tuning to perform other recognition tasks as well. Convolutional neural networks trained in this way are closely related to transfer learning. These neural networks are now widely used in many applications, such as how Facebook itself suggests certain tags in photos based on image recognition.
Current Image Recognition technology deployed for business applications
Quality control and inspection in production environments
The sector in which image recognition or computer vision applications are most often used today is the production or manufacturing industry. In this sector, the human eye was, and still is, often called upon to perform certain checks, for instance for product quality. Experience has shown that the human eye is not infallible and external factors such as fatigue can have an impact on the results. These factors, combined with the ever-increasing cost of labour, have made computer vision systems readily available in this sector.

Image recognition applications lend themselves perfectly to the detection of deviations or anomalies on a large scale. Machines can be trained to detect blemishes in paintwork or foodstuffs that have rotten spots which prevent them from meeting the expected quality standard. Another popular application is the inspection during the packing of various parts where the machine performs the check to assess whether each part is present.
Applications in surveillance and security
Another application for which the human eye is often called upon is surveillance through camera systems. Often several screens need to be continuously monitored, requiring permanent concentration. Image recognition can be used to teach a machine to recognise events, such as intruders who do not belong at a certain location. Apart from the security aspect of surveillance, there are many other uses for it. For example, pedestrians or other vulnerable road users on industrial sites can be localised to prevent incidents with heavy equipment.

Asset management and project monitoring in energy, construction, rail or shipping
Large installations or infrastructure require immense efforts in terms of inspection and maintenance, often at great heights or in other hard-to-reach places, underground or even under water. Small defects in large installations can escalate and cause great human and economic damage. Vision systems can be perfectly trained to take over these often risky inspection tasks.
Defects such as rust, missing bolts and nuts, damage or objects that do not belong where they are can thus be identified. These elements from the image recognition analysis can themselves be part of the data sources used for broader predictive maintenance cases. By combining AI applications, not only can the current state be mapped but this data can also be used to predict future failures or breakages.

Mapping health and quality of crops
Image recognition systems are also booming in the agricultural sector. Crops can be monitored for their general condition and by, for example, mapping which insects are found on crops and in what concentration. In this way, diseases can be predicted. More and more use is also being made of drone or even satellite images that chart large areas of crops. Based on light incidence and shifts, invisible to the human eye, chemical processes in plants can be detected and crop diseases can be traced at an early stage, allowing proactive intervention and avoiding greater damage.

Automation of administrative processes
In many administrative processes, there are still large efficiency gains to be made by automating the processing of orders, purchase orders, mails and forms. A number of AI techniques, including image recognition, can be combined for this purpose. Optical Character Recognition (OCR) is a technique that can be used to digitise texts. OCR, however, lacks a smart component that gives meaning to the data. AI techniques such as named entity recognition are then used to detect entities in texts. But in combination with image recognition techniques, even more becomes possible. Think of the automatic scanning of containers, trucks and ships on the basis of external indications on these means of transport.
Image & object recognition within the Trendskout AI software platform
As described above, the technology behind image recognition applications has evolved tremendously since the 1960s. Today, deep learning algorithms and convolutional neural networks (convnets) are used for these types of applications. Within the Trendskout AI software platform we abstract from the complex algorithms that lie behind this application and make it possible for non-data scientists to also build state of the art applications with image recognition. In this way, as an AI company, we make the technology accessible to a wider audience such as business users and analysts. The AI Trend Skout software also makes it possible to set up every step of the process, from labelling to training the model to controlling external systems such as robotics, within a single platform.
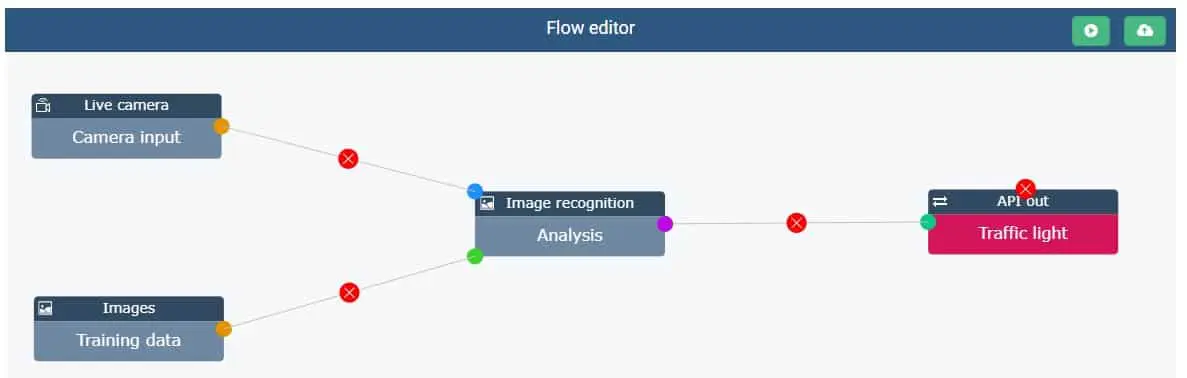
Training data input and connection for real-time AI image processing
A distinction is made between a data set to Model training and the data that will have to be processed live when the model is placed in production. As training data, you can choose to upload video or photo files in various formats (AVI, MP4, JPEG,...). When video files are used, the Trendskout AI software will automatically split them into separate frames, which facilitates labelling in a next step.
As with other AI or machine learning applications, the quality of the data is important for the quality of the image recognition. The sharpness and resolution of the images will therefore have an impact on the result: the accuracy and usability of the model. A good guideline here is that the more difficult something is to recognise for the human eye, the more difficult it will also be for artificial intelligence.
It is often the case that in (video) images only a certain zone is relevant to carry out an image recognition analysis. In the example used here, this was a particular zone where pedestrians had to be detected. In quality control or inspection applications in production environments, this is often a zone located on the path of a product, more specifically a certain part of the conveyor belt. A user-friendly cropping function was therefore built in to select certain zones.

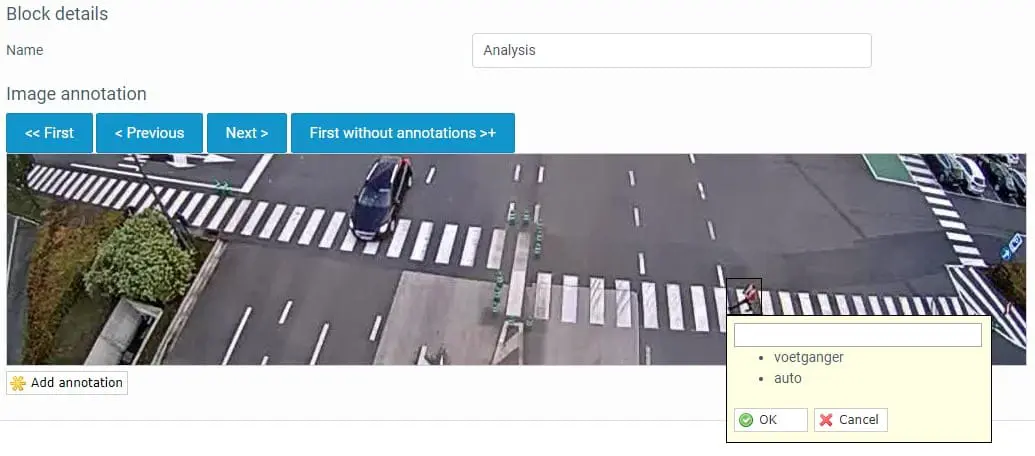
Labelling or annotating the data
In order to recognise objects or events, the Trendskout AI software must be trained to do so. This should be done by labelling or annotating the objects to be detected by the computer vision system. To do this, labels have to be applied to those frames. Within the Trendskout AI software this can easily be done via a drag & drop function. Once a label has been assigned, it is remembered by the software and can simply be clicked on in the subsequent frames. In this way you can go through all the frames of the training data and indicate all the objects that need to be recognised.
Building and training the computer vision or image recognition model
Once all the training data has been annotated, the deep learning model can be built. All you have to do is click on the RUN button in the Trendskout AI platform. At that moment, the automated search for the best performing model for your application starts in the background. The Trendskout AI software executes thousands of combinations of algorithms in the backend. Depending on the number of frames and objects to be processed, this search can take from a few hours to days. Of course, you do not have to wait for this. As soon as the best-performing model has been compiled, the administrator is notified. Together with this model, a number of metrics are presented that reflect the accuracy and overall quality of the constructed model.

Using the model for your business case
After the model has been trained, it can be put into operation. This usually requires a connection with the camera platform that is used to create the (real time) video images. This can be done via the live camera input feature that can connect to various video platforms via API. The outgoing signal consists of messages or coordinates generated on the basis of the image recognition model that can then be used to control other software systems, robotics or even traffic lights.
Do you see opportunities in your company for image or object recognition, but did the high investment costs stop you? With the Trendskout AI software platform, you can set up advanced AI use cases quickly and inexpensively. That is our mission as an AI company: to democratise AI. Contact Please contact us for a no-obligation demo, we will be happy to help.


