Een pijnlijke realiteit van zakendoen is dat klanten weggaan. Hoe succesvol jouw bedrijf ook is of hoe relevant jouw producten of diensten ook zijn, je zal steevast klanten verliezen aan jouw concurrenten.
Om die reden hebben bedrijven klantenbinding- en loyaliteitsprogramma’s om actief om te gaan met het risico op klantenverlies. In elke industrie of productsegment, van telecom tot SaaS-bedrijven en consumentenproducten, heeft churn management een directe impact op de winstgevendheid.
Afhankelijk van de bronnen die je opzoekt, en in welke industrie je actief bent, zijn de kosten voor het verwerven van een nieuwe klant vijf tot 25 keer hoger dan het behouden van een bestaande klant. Frederick Reichheld, de uitvinder van de net promoter score en auteur van “Loyalty Rules! How Today’s Leaders Build Lasting Relationships” ontdekte dat een toename van slechts 5% in klantbehoud de winst met 25% tot 95% verhoogt.
Begrijpen waarom klanten het schip verlaten is cruciaal om een duurzaam bedrijf op te bouwen. We zullen onderzoeken hoe bedrijven machine learning kunnen gebruiken om een churn prediction model te bouwen om de groei te verbeteren. Maar voordat we ons gaan verdiepen in het voorspellen van klantenchurn, kijken we eerst even naar wat het eigenlijk is.
Wat is Customer Churn Rate of klanterverloop?
Customer churn rate is een bedrijfsmetric die het percentage klanten weergeeft die hun relatie met een bedrijf in een bepaalde periode beëindigen. Dit tijdsbestek kan worden gemeten op maand-, kwartaal- of jaarbasis, afhankelijk van de branche en het product. Abonnementsgebaseerde bedrijven (denk aan mobiele dienstverleners, SaaS, en content platforms) meten meestal churn over kortere perioden.
Klantenchurn is ook een indicatie van de gezondheid van het bedrijf. Hoewel er meerdere redenen zijn waarom klanten kunnen afhaken, zijn enkele van de meest voorkomende redenen slechte service of productkwaliteit, prijs, en andere macro-economische factoren zoals een recessie.
De mogelijkheid om churn te voorspellen is de sleutel tot het voorkomen ervan. En dat is waar machine learning om de hoek komt kijken. Organisaties die voor de voorspelling van churn uitsluitend vertrouwen op feedback van klanten, zien vaak andere variabelen over het hoofd die van invloed zijn op churn.
Met de hoeveelheid data die bedrijven tegenwoordig tot hun beschikking hebben, is het veel eenvoudiger om machine learning (ML) modellen te ontwikkelen voor het voorspellen van churn. Artificial Intelligence (AI) of ML-gestuurde churnvoorspelling is nauwkeuriger dan alle andere voorspellingsmodellen die vandaag beschikbaar zijn.
Voorspellen van churn met Machine Learning
Bedrijven beschikken tegenwoordig over een enorme hoeveelheid gegevens over de manier waarop hun klanten omgaan met hun producten of diensten. Van CRM-systemen tot website-analyses en sociale betrokkenheid, bedrijven beschikken over meerdere gegevensbronnen die waardevolle inzichten kunnen verschaffen in de churnpercentages.
Met de juiste datasets kunnen algoritmen voor machinaal learning bedrijven helpen onderliggende gedragspatronen te identificeren die klanten die vertrekken gemeen hebben. De algoritmen kunnen vervolgens worden toegepast op bestaande klanten om gelijkaardig klantgedrag en churn-indicatoren te detecteren.
Een mobiele serviceprovider die opzeggingen wil voorspellen, kan bijvoorbeeld historische klantgegevens gebruiken om vast te stellen welke klanten de service hebben opgezegd of hun maandelijkse factureringsplannen hebben verlaagd. Het bedrijf kan deze gegevens vervolgens gebruiken om een machine learning model te trainen om gedragskenmerken tussen churners en non-churners te vergelijken.
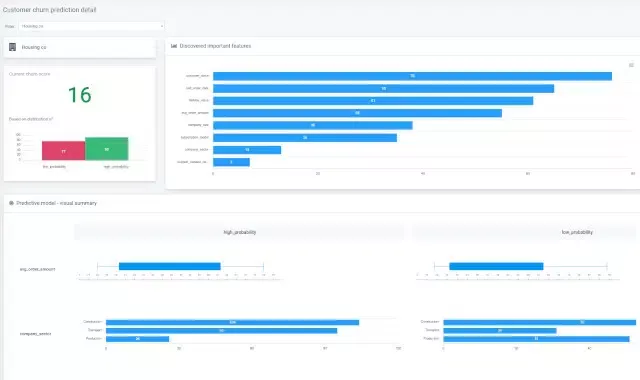
Het ML-model zal kijken naar attributen zoals woonplaats, levensduur van de klant, actieve plannen, dagelijkse gesprekken, dagelijks dataverbruik, maandelijkse plannen/factuurbedrag, en het aantal gesprekken met de klantenservice om de waarschijnlijkheid van churn te bepalen.
Hoe bouw je een churn prediction model: Een stap-voor-stap uitsplitsing
Het is duidelijk dat historische gegevens een eerste vereiste zijn om een churn-voorspellingsmodel op te bouwen. Naast gegevens zijn er echter nog verschillende andere factoren die zullen bepalen hoe je jouw churn prediction model opbouwt. Hier zijn de stappen om het te creëren.
1. Bepaal de business case
Deze stap is simpelweg het begrijpen van jouw gewenste resultaat van het ML-algoritme. In dit geval is het einddoel:
- Klantchurn voorkomen door preventief risicoklanten te identificeren
- Ontwerp passende interventies om de retentie te verbeteren
2. Gegevens verzamelen en opschonen
De volgende stap is het verzamelen van gegevens – begrijpen welke gegevensbronnen jouw churn prediction model zullen voeden. Bedrijven verzamelen klantgegevens gedurende de gehele levenscyclus via software zoals CRM, webanalyse, sentimentanalyse tools, social listening tools, klantenservicesoftware en meer.
Het bouwen van datacaptatiediensten is een van de gemakkelijkste en meest effectieve manieren om te beginnen met het verzamelen van gegevens voor jouw churn prediction model. Een grote stap in de voorbereiding van gegevens is het transformeren van al deze ruwe informatie in gestructureerde gegevens.
3. Ontwikkel, extraheer en selecteer kenmerken
Feature engineering is een cruciaal onderdeel van de voorbereiding van de dataset – het helpt bij het bepalen van de attributen die gedragspatronen vertegenwoordigen met betrekking tot de interactie van klanten met een product of dienst. Data scientists gebruiken feature engineering om meetbare kenmerken toe te wijzen aan datapunten die een ML-model zal verwerken om de kans op churn te voorspellen.
Deze kenmerken kunnen bestaan uit demografische gegevens van de klant, gedrag (in het voorbeeld van de mobiele telefoon kan dit zijn: dataverbruik, bellen met de klantenservice, gebruik van internationale roaming, enz.) en contextuele kenmerken die andere informatie over een klant beschrijven, zoals communicatievoorkeuren, koopgedrag in het verleden of verjaardagen/verjaardagen.
Vervolgens standaardiseert feature-extractie de variabelen (attributen) door alleen die variabelen te isoleren die zinvolle informatie bevatten in de context van de business case (churn). Feature extractie beperkt de datadimensionaliteit (kolommen die attributen in een dataset vertegenwoordigen) en behoudt alleen nuttige gegevens voor de business case.
Feature selectie verwijst naar een data science techniek die eerder geëxtraheerde features identificeert en subgroepen selecteert die het meest van invloed zijn op de doelvariabele (churn). Dit leidt tot een dataset die alleen de meest relevante informatie bevat over kenmerken die van invloed zijn op de churn.
4. Bouw een voorspellend model
Data-analisten benaderen de voorspelling van churn meestal met behulp van meerdere methoden, zoals binaire classificatie, logistische regressie, decision trees, random forest, en anderen.
ML-algoritmen voeren binaire classificatie uit om de attributen van een doelvariabele in twee groepen in te delen op basis van een classificatieregel. In deze context is de doelvariabele churn, waarvan de uitkomst kan worden geclassificeerd als waar of onwaar. Binaire classificatie helpt ons te begrijpen welke klanten afhaakten en welke klanten bleven.
Doe je een beroep op Trendskout, dan hoef je natuurlijk geen data scientist aan het werk te zetten. Dat gebeurt allemaal in het platform. Door snelle ittiraties kiest het slimme AI en ML platform van Trendskout de juiste modellen.
Op basis van deze informatie kunnen data scientists vervolgens regressieanalyse uitvoeren om de relatie te bepalen tussen de doelvariabele (churn) en andere datapunten die churn beïnvloeden (maandplan, dataverbruik, service calls, etc.), in gewogen waarden.
Dit zal informatie opleveren over de vraag of variabelen een positieve of negatieve relatie hebben met churn. Een positieve relatie wijst op een grotere kans dat klanten afhaken en een negatieve relatie betekent dat klanten minder snel zullen afhaken.
Een beslissingsboom of decision tree is nog een ander doeltreffend opleidingsmodel voor de voorspelling van opzeggingen. Het beslissingsboommodel gebruikt de beschikbare kenmerken en splitst de gegevens op basis van de waarden van de kenmerken om unieke resulterende groepen te verkrijgen. Hier is een eenvoudig voorbeeld van een beslissingsboom:
Afhankelijk van de grootte van de dataset en de diversiteit van de feature data, kan je ervoor kiezen om meerdere beslisbomen of een Random Forest te gebruiken.
Een Random Forest is een verzameling van meerdere beslisbomen, waarbij elke individuele boom een classificatie uitsplitst. Deze classificaties zijn binair van aard, dus de classificatie die de meeste stemmen krijgt, wint. Dus, als je Random Forest bestaat uit vijf beslisbomen, en drie daarvan geven dezelfde classificatie, dan zal je uiteindelijke voorspelling worden bepaald door de meerderheid.
5. Implementeren en controleren
Zodra je het model hebt ontwikkeld, moet het worden geïntegreerd in bestaande software of dienen als basis voor een nieuw programma of toepassing. Je moet de nauwkeurigheid en de prestaties van het model nauwlettend in het oog houden.
Door de prestaties van het model te testen en te controleren om de functies aan te passen, kan je de nauwkeurigheid van het model verbeteren. In ons voorbeeld van mobiele diensten kunnen monitoring en testen het loggen van klantinteracties en beoordelingen betekenen.
Verbeter de inkomsten met de voorspelling van klantenchurn
De belangrijkste factor bij het aanpakken van churn is het ontwikkelen van een churn prediction model . Het model vertelt je niet alleen wie jouw risicoklanten zijn, maar biedt ook inzicht in de redenen waarom ze zullen vertrekken. Voor marketeers en customer succes managers is dit de heilige graal voor het oplossen van het leaky bucket probleem – het ontdekken van de onderliggende redenen voor klantverloop.
Klantbehoud komt neer op het vermogen van een bedrijf om de motivaties achter opzegging te analyseren en te voorspellen en, nog belangrijker, ernaar te handelen. Hoe groter jouw klantenbestand, hoe groter de impact van churn.
Wilt je jouw omzetresultaten verbeteren met churn prediction? Geïnteresseerd in het aanboren van gemiste datakansen die leiden tot bedrijfsgroei? Laten we eens praten over hoe we machine learning kunnen gebruiken om nauwkeurige churn prediction te implementeren voor jouw bedrijf.
Neem contact met ons op voor meer informatie.


